 2024 REPORT
2024 REPORT

 2024 REPORT
2024 REPORT
光電融合技術とスーパーコンピュータの未来
登壇者
NTT先端集積デバイス研究所・NTT物性科学基礎研究所
フェロー
松尾 慎治 Shinji Matsuo
株式会社Preferred Networks
代表取締役 最高経営責任者・共同創業者
西川 徹 Nishikawa Toru
2024年11月29日に開催されたNTT先端集積デバイス研究所・物性科学基礎研究所 松尾 慎治 フェローと株式会社Preferred Networks 西川 徹CEOが登壇した技術セミナー「光電融合技術とスーパーコンピュータの未来」の様子をお伝えします。

パッケージ内光インターコネクションに向けたメンブレン化合物半導体デバイスの研究開発の紹介
NTT先端集積デバイス研究所・NTT物性科学基礎研究所
フェロー 松尾 慎治
データ通信の高速化と消費電力化の両立
本日は光電融合デバイスのパッケージ内の「光インターコネクション」に注力し、なぜ光とコンピューティングに近づくのかをご説明します。現代ではI/O機器がどんどん増えてきて、Googleデータセンタのように原発を1個隣に置かないといけないほどのエネルギーが必要といわれています。そのデータセンタは世界の電力の2%使用しており、日本の場合は首都圏にデータセンタが集中し国内電力の12%を使っています。我々NTTも日本の総電力の0.7〜1%を使用していることから、消費電力の改善を目的としています。
私は光技術の専門家なので、光技術の歴史にも簡単に触れておきます。伝送には電気配線と光ファイバーがあり、電気配線はスピードが遅くて伝送距離が短いときに有利で、伝送距離が伸びたりスピードが上がる場合は光が有利です。今から40年ほど前から県間網などで使用され始めた光ファイバーは、今では海底ケーブルに至るまで伸びています。しかし、光のほうが通信スピードが高く効率が良いため、データセンタやスーパーコンピュータは平均20mほどの短い距離でもほぼ光を使っています。そして光の消費電力の上昇をさらに加速させているのが近年のAIです。
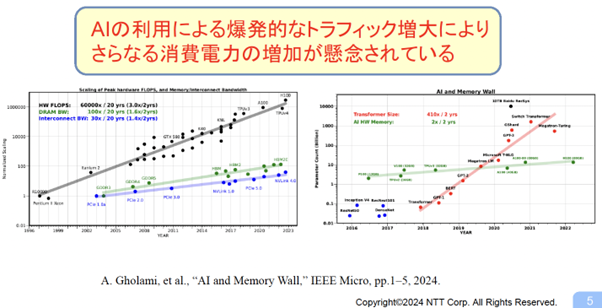
(図1)左図の黒い線はコンピュータのパフォーマンスの上昇、緑がメモリの伸び、青が通信スピードの伸びです。どう見てもギャップが広がる一方で、これをメモリギャップといいます。それをさらに加速したのが右図です。インターネットの使用量に加え、赤で示すAIがそれを上回るスピードで上昇しており、通信に必要な電力が増加してきています。この短い距離で消費電力の高い部分が、我々のターゲットであり改善すべき点です。
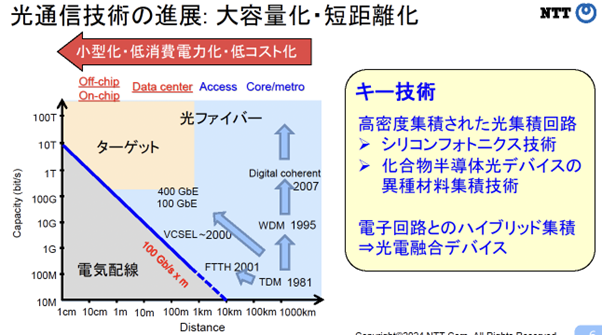
留意すべき点としては、スペースに限りがあるため小型であり、そして低消費電力で低コストでなければなりません。この3つを実現させるために、光集積回路(電子部品を1つのチップ(基盤)に搭載したもの)を活用します。
具体的には、シリコンのCMOS(Complementary Metal Oxide Semiconductor,相補型金属酸化膜半導体)プロセスを使ったシリコンフォトニクスという、シリコン上に光と電子の集積回路を制作する技術を使います。光集積回路に必要な送受信機は「化合物半導体」で光を作って飛ばすのですが、そこでは「異種材料集積技術」(異なる素材でつくられる高性能光デバイス)も重要となります。
そうしてつくられた光集積回路がさらに電子デバイスと3次元に集積し、電気と光を密に融合させたものが、「光電融合デバイス」といいます。(図2)
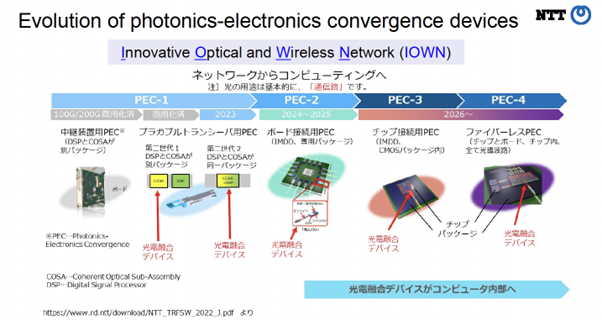
光電融合デバイスのロードマップ(図3)ですが、遠いところから近いところまで、最後は「ボード」の中まで光を導入することを目指しており、その時により近い位置設置される光電融合デバイスが重要になります。もう1つポイントとして、今まで通信を専門としてきたNTTですがここまで距離が近くなるとコンピューティングにも入っていく必要がでてきています。
目指す時期が設定されており、研究所的には時間がなく焦りを感じているのが正直なところです。現実的な問題として、LSI(Large Scale Integration.大規模集積回路)から電気の配線を通して光を出す際、電気の配線のところで膨大なエネルギーを使用することで無駄が生じており、光部分を物理的に寄せて密接させることで無駄を省く取り組みが世界的な流れです。しかし、電子デバイスと比べて、光デバイスは壊れやすく取り替えも困難なため、低コストで耐久性のある信頼性が高い高品質なレーザーを作ることも研究課題となっています。
演算に割り当てられる電力の確保と、「光化」によるハードウェアの物理的な位置に依存しない計算資源の有効利用
LSIの「光化」の必要性についてもお話しします。光化の理由はやはり消費電力が関係するのですが、CPUチップ(Central Processing Unit.パソコンの脳にあたる部分)の消費電力は一定の割合で増加していることに比べ、オフチップ(外部メモリ)の通信量は指数関数的に増加しています。そうなると電気配線や排熱にもエネルギーを消費することになります。この電力の増加が進むと、コンピュータを動かす「演算」に使用する電力がなくなるため、「光化による低消費電力化」が必要になります。
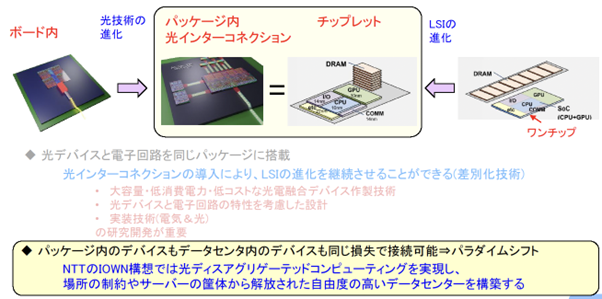
また、一般的なLSIの電子回路についても説明すると、元々ひとつのチップを使用していましたが、チップの肥大化に伴いチップレット(細分化して適材適所に活用する)という技術がでてきました。そうなると、分かれて設置された「チップ間の通信」も重要になります。
その一般的なLSIのチップレットと、我々のめざす「パッケージ内の光化」は同じで我々の実現したいところでもあり、光インターコネクションの導入により、LSIの進化を継続できるのではと考えています。(図4)
また,光は2cm飛ばしても、2km飛ばしても伝送損失は同じで0.2dbしかありません。そのためディスアグリゲーテッドコンピューティング(多種類のコンピューティングリソースを、長距離・広帯域・低消費電力な光電融合技術を利用して相互につなぐこと)のようなものが実現できます。実際にアメリカの企業では、300mmウエハ(半導体集積回路の材料となる薄い板)の中に光回線や電気を実装する話も出てきています。
このように光は伝送が得意なため、距離が長くなるほど光を使う可能性が高くなります。またNTTが出しているディスアグリゲーテッドコンピューティングでは、メモリ不足解消のためいろいろな箇所からメモリを集めてスケーラブルにしており、ボード上の電気では対応できない領域をターゲットとしています。
半導体とシリコンを集積した「光電融合デバイス」の重要性
先ほどシリコンフォトニクスの話をしましたが、シリコンは電子回路を作れても、レーザは作れません。現在は0.5ミクロン幅の光の導波路に置くのですが、そこの位置を合わせることに非常にコストがかかります。本日の展示会ではウエハレベルで作れることを紹介していますが、従来のレーザより薄膜にすることで多くのメリットが生まれました。その結果、シリコンフォトニクスと非常に相性の良い光電融合デバイスができあがり、今では16chのレーザアレイを置いて1.6tbの信号を出すところまで研究開発が進められています。
そこには光電融合デバイスが重要で、そのチップと外ハブで作ったCMOSのドライバサーキットを3次元的に集積することで、距離が短く非常に低消費電力のものができます。このとき電子回路と光回路を別々に設計せずトータルで考え,いかに安く・早く・低消費電力で動かすのかが大事です。これからはこの光電融合デバイス化が非常に重要な技術になると考えています。(図5)

サステイナブルなAIを目指して
株式会社Preferred Networks
代表取締役 最高経営責任者・共同創業者 西川 徹
我々はまだ「光電融合技術」は使っていませんが、生成AIや基盤モデルといったインターコネクトを非常に重要とする世界において、これからは間違いなく低消費電力や低コストでの製造は重要になってくると考えています。
また、これまでの機械学習AIに比べて今の生成AIは計算インセンティブによりアーキテクチャ(システムの骨組みや設計)のバランスが変わり、アーキテクチャそのものも変わってきています。では、我々はどのようなアーキテクチャをめざすべきなのかをお話しします。
まず、我々はソリューション・製品、生成AI・基盤モデル、計算基盤、そしてそれを動かすためのAIチップの制作など、垂直統合型で4階層の技術を作っています。取り組みの理由として、生成AIや基盤モデルというのはポテンシャルが分からない部分が多くあり、さまざまなレイヤーを研究開発して機動力よくそのポテンシャルを突き詰めていくフェーズだと考えているからです。(図6)

また、先ほど松尾フェローからありましたように、現代では消費電力が非常に大きな問題になっています。最先端AIシステムに求められる計算力は指数関数的に上がり、世界最高精度のスーパーコンピュータの計算能力を遥かに越える状況になっています。その反面で消費電力やコストも上がり、高度なAIを使うことでエネルギーは低減できても、それを上回る大量の電力を使用するという矛盾を抱えている状況です。AIを研究する者としては、この消費電力をいかに減らすことも非常に重要です。その打開策として、我々は2016〜2019年ころに「MN-Core」という専用AIチップを開発し、2020〜2023年にはバージョン2を発表しました。
そもそもなぜチップを開発したのかというと、当時からGPU(Graphics Processing Unit, 画像処理装置。AIでは高速並列処理として使用される)の不足が問題で、出荷量が10万枚あったとしても不足していました。AIにとって計算力や消費電力が大切な生命線であり、この生命線をいかに確保するのかが非常に重要な課題でした。この心臓部分を確保するため、自分達で開発を始めました。
省電力化の方法としては、トランジスターの多くの部分を演算器とSRAM(Static Random Access Memory, 半導体の一種)と呼ばれるオンチップメモリ(1枚のチップの上にすべて搭載した状態)で占めて、制御回路は最小限にしてソフトウェアに任せることで、大幅な電力の低下に成功しました。(図 7)
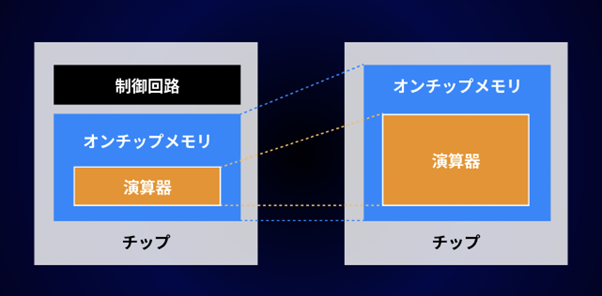
現在はこれを社内で使用おり、アーキテクチャを工夫することによって低消費電力で、低価格なプロセッサを作れると考えています。現在は第3世代・第4世代の開発に着手しており、2026年からは代販(代理店を挟んで販売)を予定しています。
それに加えて、MN-Coreのソフトウェアに関してはコンパイル(プログラミングコードを機械語に翻訳変換すること)な部分にも注力しており、ソフトウェアとハードウェアをうまく融合させることで、対応するAIモデル数を日々増やしています。
少し前の話になりますが、我々が開発したものが「コンピューターランキング」の世界1位を計3回獲得できました。非常にエキセントリックなアーキテクチャなのですが、ソフトウェアとハードウェアを組み合わせることで、使いやすさとコストパフォーマンスを兼ね備えた「新しいアーキテクチャ」であると証明できたように思います。
今後のロードマップは、アーキテクチャの仕様が大きく異なる「推論」と「学習」をふたつに分けて、それぞれに最適なアーキテクチャの実現を目指しています。例えば推論はほとんど演算を使わず、メモリやインターコネクトなどを多用するため、光電融合のような高速で低消費電力な仕組みが必要です。このように、現在はパッケージングを始めとする新しい技術を用いて、柔軟かつ用途に応じた適切なプロセッサ作りに取り組んでいます。(図8)
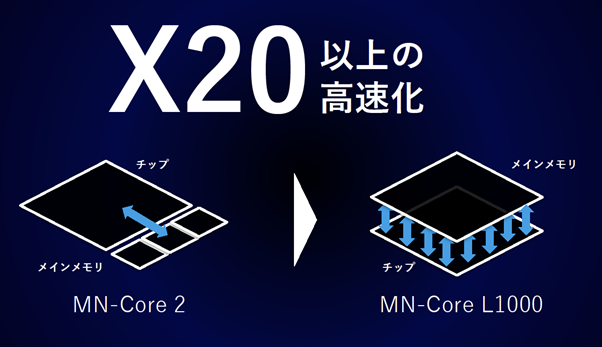
大型のスーパーコンピュータ的な計算機は複雑なエコシステムにより形成されるのですが、日本の中で優れたエコシステムを構築し、どんどん新しい技術を取り込みながら成長させていくことが重要だと考えています。
これからは「計算機をスケールする技術」もますます重要になります。もちろんLLMにおける計算機のスケールも重要ですが、LLMだけでAIの世界が終わるわけではありません。計算機の高速化によってできることが増えてきており、それを実現するためには高効率のAIチップとインターコネクトやチップレットをはじめとするさまざまな技術のインテグレーション(複数の異なるものを統一させること)が必要だと考えています。
ディスカッション
MN-Coreをつくるまでの経緯の詳細
- 松尾 フェロー
- 演算に使う電力が脅かされるなかで、不要なものを外に出し、ソフトウェアで制御して演算にスペースを与える,という考えに非常に感銘を受けました。
私の知っている限り、Preferred Networksは検索エンジンやAIを開発していたと思うのですが、MN-Core開発が重要だと考えた経緯をもう少し詳しく聞かせてください。 - 西川 COO
- 2016年当時、日本ではGPUの入手が非常に困難で、何とか1024枚のGPUを購入できたのですが、入手するまでの交渉は非常に厳しいものでした。日本でもアーキテクチャを販売する企業はありましたが、ソフトウェアで弱い部分があり、このままではいずれGPUが手に入らなくなると思いました。ディープラーニングの中でも我々が理想とするワークロード(コンピュータにかかる処理負荷の大きさ、GPU使用率など)を実現する目標がありましたので、自分達の理想とするアーキテクチャがないのなら、自分達で作ろうという流れになりました。
それに加えて、私がハードウェアをつくることに魅力を感じていたことも大きいと思います。大学時代の指導教官がハードウェアの研究室にいたのですが、その先生は当時スーパーコンピュータが1000億かかる時代に「20億で低消費電力のプロセッサをつくるぞ」みたいな話をされていて私の中ではすごい衝撃でした。結果的に、所望の性能を出すのは難しかったのですが、かなり良い性能を出せました。
そういった流れを見ていく中で、スーパーコンピュータをつくるのがとても面白いことだと感じてこの世界に入り、MN-Coreの開発に繋がったと思います。 - 松尾フェロー
- スーパーコンピュータをつくるなど、ハードウェアをつくるときは設計がとても重要になります。Preferred Networksはソフトウェアの研究者が多いと思いますが、ハードウェアの研究をどう加速していくのか、人を集め、会社的に成果をだしていく際に心がけていることはありますか。
- 西川 COO
- 現在ハードウェアを開発しているメンバーは80人ほどおり、どれだけ入念に検証するか、ということに物凄く力を注いでいます。ハードウェアのテストベクタ(設計内容を評価するデータ)を書くときもいろいろなパターンを試行錯誤し、テストベクタやテストケースを書くなど、できる限りバグが起きないようにしています。バグが起きたとしてもそれをどうやって防ぐかというワークアラウンドに力を入れています。
未来のスーパーコンピュータとAI
- 松尾 フェロー
- メモリ不足の問題では、メモリとCPUを3Dでくっつけて、通信のエネルギーや速度帯域を上げる話をされていました。NTTではディスアグリゲーティッドコンピューティングという話をしましたが、データセンター全体をつかったコンピューティングはAIで使えるものがあるのでしょうか。
- 西川 COO
- データセンタ自体の性能を上げていくことはもちろん、スーパーコンピュータの設計にAIを活用することも必要だと思っています。スーパーコンピュータは非常に複雑なシステムで、その複雑さは今後増していくといわれています。その複雑化したスーパーコンピュータを安定して動かすためには正確な設計が大事で、人間が行うのは非常に難しいことです。そこでAIの活用が期待でき、これからはAIと人がどのように協調してコンピュータを作るのかが重要だと思います。
- 松尾フェロー
- AIがあまりに膨大に設計してしまい、その正誤判定や検証を人間が行うのも難しく、AIに判断を任せると間違ったものも正しいと判断する可能性もあります。この対策はどうするのでしょうか。
- 西川 COO
- 正誤判定や検証にAIを活用するためには、最初は小さな回路から順に育て、ノウハウを積み上げることが必要です。今後はコンピュータがコンピュータを設計するという流れになると考えています。そこでは、人間にできること・できないことを,切り分けなければなりません。最初はその切り分け自体が職人芸になると思います。それをうまく使いこなして新しい設計手法を見出していくことが、新たな半導体をつくる上で非常に重要です。
ほかにもパッケージングの階層や、排熱の複雑化、半導体のレイヤー同士のインテグレーションなど、人間では難しいことがたくさん出てくると思いますが、そこまで踏み込んで設計することで「日本にしか出せない価値」がでると考えています。 - 松尾フェロー
- ディスアグリゲーテッドコンピューティングにも関するところですが、今の課題はボードのつなぎ方で、コンパクトなLLMと大きな規模では、必要なアーキテクチャが異なります。臨機応変に使えるアーキテクチャがなければ、将来のスーパーコンピュータを効率的に動かせないと思います。そこでMN-Coreの作り方についても伺いたいのですが、1個で全部の計算をするのか、それとも何個もつないで計算するのでしょうか。
- 西川 COO
- MN-Coreのバージョン1は4つの台をつなげ、バージョン2は1つの台になり、今のバージョン3は密度を高める方向に移ってます。そして、推論と学習を分けることで、効率良く動けて容積的にも短く小さくすることで、演算量は10分の1とか20分の1くらいまで下がります。また,電力の供給だけではなく排熱も重要なため、シミュレーションを駆使して排熱と電力消費のバランスを考えながら研究開発を進めています。
研究チームや皆様へのメッセージ
- 松尾 フェロー
- ハードウェアの研究は当たり外れや手探りのことが多く、そこに向けて一生懸命にやるのはとても大変なことです。我々は世の中に役立たせるため、パートナー企業の会社とともに非常に苦労して進めていますが、NTTの研究所は半官半民のところがあるので、地球全体・社会全体を考える必要があります。極端な話をすると、インターネットをより高速に安くするなら使わなければいいだけの話ですがそれは非現実的で、そこを打ち破れるのがAIだと思っています。現在はAIのエネルギー消費が問題視されていますが、これからは我々や西川COOの技術を使い、AIで省エネができる世界をめざすことが大事だと思います。また、AIはデバイスなど設計分野以外にも活用できると考えています。例えば工場のライン管理などでも活用でき、AIがモニターを監視して何かあればアラームを出し修正する、などサステナブルな工場ができるのではと思います。
- 西川 COO
- ハードウェアとソフトウェアの合わせ技、そのバランスがスーパーコンピュータにおいてますます重要になると思います。我々はよく「何をしている会社なのか」と聞かれるのですが、ハードウェアとソフトウェアをバランスよく融合させることで起こせるイノベーションを目指しています。そのためには両方研究していなければいけません。AIによる自動化もいずれ鈍化するかもしれませんが、一方でエンターテイメントや新しいデバイスなど、低消費電力で新しい素材を使ったエッジデバイスの世界観は、これからも生まれ続けると思います。
また、ハイブリッドで人々を豊かにしていく会社はほとんど日本にはない中で、NTTの取り組みは非常に素晴らしいもので、とても感銘を受けています。