03/05/2021
Initiatives to Create Future Information-processing InfrastructureNTT Software Innovation Center
*The names of the laboratories mentioned in the article may have changed since the time of writing/interview.
Feature Articles: Future Information-processing Infrastructure for Enabling Data-centric Society, NTT Technical Review, February 2021.
Seiji Kihara, Hiroyuki Tanaka, and Yutaka Arakawa
1. Circumstances surrounding information-processing infrastructure
The process of solving real-world problems using various real-world data is becoming increasingly important. There are countless examples of such processes in manufacturing, such as production management and facility-failure prediction based on plant operation data, and in retail, such as supply-and-demand prediction based on weather data, marketing, and flow-line design based on customer-behavior data. We call this process data-value creation. In addition to intensifying competition among companies and aggravating environmental and social problems, the shift to a remote society accelerated by the COVID-19 pandemic has prompted a digital transformation of society as a whole, and expectations for data-value creation are increasing. Against this backdrop, we believe that a data-centric society will arrive in which value will be created from data from all aspects, such as decision-making, optimization, and forecasting. The role of an information-processing infrastructure, which is the foundation of the distribution and analysis of a large and diverse amount of data, will become more important.
Looking back on technological history, the current information-processing infrastructure has continuously evolved. From the viewpoint of the system infrastructure, processor performance was first improved by speeding up the single-core central processing unit (CPU) by refinement then adopting a multi-core architecture. The whole system was initially sped up and became more sophisticated by processing using a single server and later by distributed and parallel processing using multiple servers. For software development, the waterfall-development method has long been used for developing large-scale, high-quality software such as mission-critical systems, and the agile development method has recently been widely adopted for developing web applications that require usability and rapid development. As the data-centric society progresses, the evolution of such technology is expected to continue.
On the basis of these circumstances, NTT Software Innovation Center (SIC) is working on research and development (R&D) to support a data-centric society and create a future system infrastructure and software-development methods that respond to the evolution of society and technology in cooperation with other NTT laboratories that specialize in hardware, security, and other related technologies.
2. R&D supporting a data-centric society
Figure 1 shows the general flow of data-value creation in a data-centric society. First, in various real-world places, data about real-world objects and events are generated, collected, and accumulated as sensing data and log data. Next, the data are analyzed and converted. Then, actions affecting the real world are taken to solve problems. In many cases, by repeating this flow, we can gradually mitigate problems even if the real world continues to change. By feeding data back into the real world in this manner, we can move the real world in a positive direction and provide value to customers in various domains.
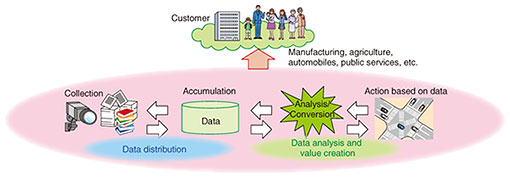
To support the value chain of such a data-centric society, we are researching and developing the following basic information-processing technologies.
(1) Data analysis and value-creation technology
The application scope of data-value creation is thought to be wide, so value cannot be created in a uniform manner. What value can be created from what data by what analysis? We believe that to find a truly useful means to create value, we need to confront specific issues in each domain and take a trial-and-error approach to finding the right combination from the various available data and analytical methods. To create value from data in various situations, it is essential to improve the efficiency and sophistication of trial and error. Therefore, we are engaged in R&D to achieve this and even automating it.
Even if one finds a means to create value from one's data, it will not be a viable solution if the amount of data one needs to process is so huge that one cannot create value in the expected amount of time or at a lower cost than that one wants to create. For example, the application of artificial intelligence (AI) technology, which is expected to be used for data analysis, has been expanding as it becomes more sophisticated, while the increasing amount of processing has become a problem. In the article "An Efficient Event-driven Inference Approach to Support AI Applications in IOWN Era" [1] in this issue, we introduce technology that improves the efficiency of AI-inference processing for large amounts of video data to develop AI services that exceed human capacity in the Innovative Optical and Wireless Network (IOWN) era.
(2) Data-distribution technology
New technology is also needed to efficiently collect data to be analyzed. Not all real-world data are readily available. In some cases, it may not be possible to obtain all necessary data due to sensor failure, measurement timing, etc. In other cases, data may not be available due to privacy or business reasons. In addition, data are generated or accumulated in various places in the real world, which causes problems such as network and storage performance and capacity being squeezed by data collection and replication and the data owner's authority and lifecycle management of replicated data becoming out of reach. As one approach to solve such problems, we introduce the next-generation data hub technology in cooperation with other NTT laboratories, such as NTT Secure Platform Laboratories, in the article "Next-generation Data Hub Technology for a Data-centric Society through High-quality High-reliability Data Distribution" [2] in this issue. Our goal is to create a data-centric society in which vast amounts of data generated around the world are not only used within closed organizations, such as corporations, but also widely distributed and used to create new value by combining other data and expertise never encountered before.
3. R&D of system infrastructure and software-development methods that respond to the evolution of society and technology
With the progress in the information society, the volume of data distribution and analysis will increase explosively, and the system infrastructure will require further performance improvement. In addition, new services using a wide variety of data will appear, and their individualization and customization will accelerate; thus, more efficient and high-speed software-development methods will be required.
In response to this evolution, we are engaged in the following R&D to continue and accelerate the evolution of the system infrastructure and software-development methods.
(1) System-infrastructure technology
It has been said that Moore's Law is reaching or has reached its limit. This means the end of an era when system performance was heavily dependent on CPU performance. In the new era, the effective use of application-specific hardware, such as GPUs (graphics processing units) and FPGAs (field programmable gate arrays), is considered to be a major technical problem for achieving high-speed and high-efficiency data processing. To solve this problem, we are conducting R&D in cooperation with NTT Device Technology Laboratories, which researches and develops optical interconnect technology that connects various computing resources at high speed, and NTT Basic Research Laboratories, which researches and develops Ising computers that solve problems at high speed with photonics technologies. We introduce the technology for specializing processing using application-specific hardware and the parallel processing of CPUs with many cores to create a system infrastructure that enables high-speed and high-efficiency data processing beyond the limits of Moore's Law in the article "Software Innovation for Disaggregated Computing" [3] in this issue.
(2) Software-development technology
To meet the diversifying and blurring requirements of business and keep up with the speed of business evolution, we are researching and developing technologies for AI that substitute for and transcend some of the human work required in software development. With these technologies, we aim to develop a high-speed development method with which AI and humans can work together.
As one such AI-development technology, we introduce a test automation technology that greatly improves the efficiency of the test process and ensures quality assurance by accurately and intensively testing areas of questionable quality by collecting and analyzing actual test-activity data in the test process in the article "Test Automation Technology for Analyzing Test-activity Data and Detecting Bugs" [4] in this issue.
4. Future directions
To create future information-processing infrastructure that supports a data-centric society and adapts to the evolution of society and technology, various problems described in this article need to be solved. Through collaboration with partners in various industries and experts in academic and technological fields, we aim to establish various technologies as soon as possible.
References
- [1]T. Eda, R. Kurebayashi, X. Shi, S. Enomoto, K. Iida, and D. Hamuro, "An Efficient Event-driven Inference Approach to Support AI Applications in IOWN Era," NTT Technical Review, Vol. 19, No. 2, pp. 41–46, Feb. 2021.
https://ntt-review.jp/archive/ntttechnical.php?contents=ntr202102fa4.html - [2]S. Mochida and T. Nagata, "Next-generation Data Hub Technology for a Data-centric Society through High-quality High-reliability Data Distribution," NTT Technical Review, Vol. 19, No. 2, pp. 47–52, Feb. 2021.
https://ntt-review.jp/archive/ntttechnical.php?contents=ntr202102fa5.html - [3]T. Ishizaki, S. Nakazono, H. Uchiyama, and T. Komiya, "Software Innovation for Disaggregated Computing," NTT Technical Review, Vol. 19, No. 2, pp. 53–57, Feb. 2021.
https://ntt-review.jp/archive/ntttechnical.php?contents=ntr202102fa6.html - [4]H. Tanno, H. Kirinuki, Y. Adachi, M. Oinuma, and T. Muramoto, "Test Automation Technology for Analyzing Test-activity Data and Detecting Bugs," NTT Technical Review, Vol. 19, No. 2, pp. 58–62, Feb. 2021.
https://ntt-review.jp/archive/ntttechnical.php?contents=ntr202102fa7.html